Testing indirect effects/mediation in R
What is mediation?
There are many ways to define mediation and mediators. Here’s one way: Mediation is the process by which one variable transmits an effect onto another through one or more mediating variables. For example, as room temperature increases, people get thirstier, and then they drink more water. In this case, thirst transmits the effect of room temperature on water drinking.
What is an indirect effect?
The indirect effect quantifies a mediation effect, if such an effect exists. Referring to the thirst example above, in statistical terms, the indirect effect quantifies the extent to which room temperature is associated with water drinking indirectly through thirstiness. If you’re familiar with interpreting regression coefficients and the idea of controlling for other variables, then you might find it intuitive to think of the indirect effect as the decrease in the relationship between room temperature and water drinking after you’ve partialed out the association between room temperature and thirtiness. In other words, how much does the coefficient for room temperature decrease when you control for thirstiness?
Model and Conceptual Assumptions
- Correct functional form. Your model variables share linear relationships and don’t interact with eachother.
- No omitted influences. This one is hard: Your model accounts for all relevant influences on the variables included. All models are wrong, but how wrong is yours?
- Accurate measurement. Your measurements are valid and reliable. Note that unreliable measures can’t be valid, and reliable measures don’t necessairly measure just one construct or even your construct.
- Well-behaved residuals. Residuals (i.e., prediction errors) aren’t correlated with predictor variables or eachother, and residuals have constant variance across values of your predictor variables. Also, residual error terms aren’t correlated across regression equations. This could happen if, for example, some omitted variable causes both thirst and water drinking.
Libraries
# install.packages("tidyverse")
# install.packages("knitr")
# install.packages("lavaan")
# install.packages("psych")
# install.packages("MBESS")
library(tidyverse)
library(knitr)
library(lavaan)
library(psych)
library(MBESS)Data
I took the data from Table 3.1 in Mackinnon (2008, p. 56) [mackinnon_2008_t10.1.csv]
thirst.dat <- read_csv("data/mackinnon_2008_t10.1.csv")Print first and last five observations
thirst.dat %>%
headTail() %>%
kable()| id | room_temp | thirst | consume |
|---|---|---|---|
| 1 | 69 | 2 | 3 |
| 2 | 70 | 2 | 4 |
| 3 | 69 | 1 | 2 |
| 4 | 70 | 3 | 2 |
| … | … | … | … |
| 47 | 71 | 4 | 4 |
| 48 | 71 | 4 | 5 |
| 49 | 70 | 3 | 3 |
| 50 | 71 | 4 | 3 |
Visualize relationships
It’s always a good idea to look at your data. Check some assumptions. See
help(pairs.panels)for details.
thirst.dat %>%
select(room_temp, thirst, consume) %>%
pairs.panels(scale = FALSE, pch = ".")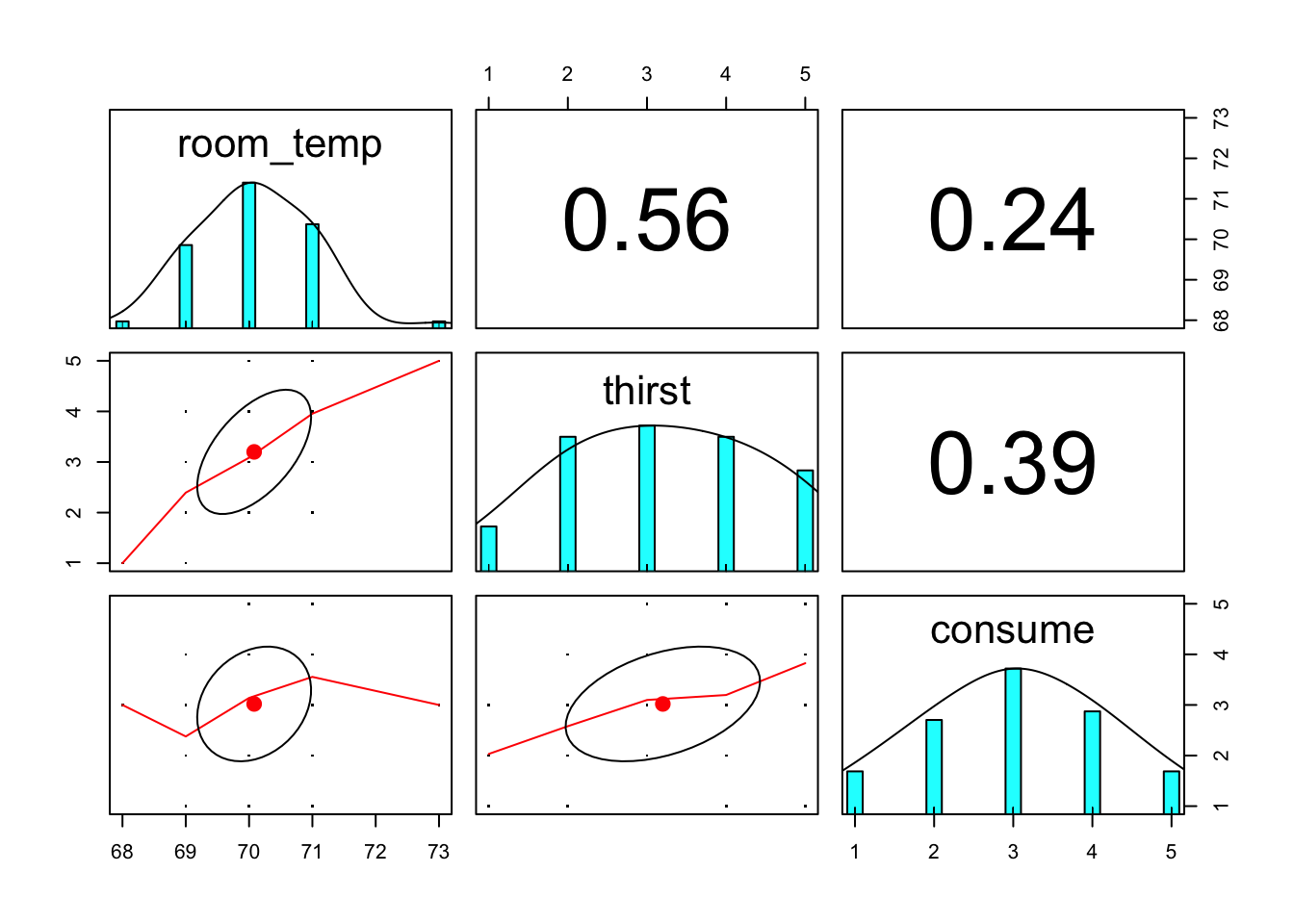
Conceptual Diagram
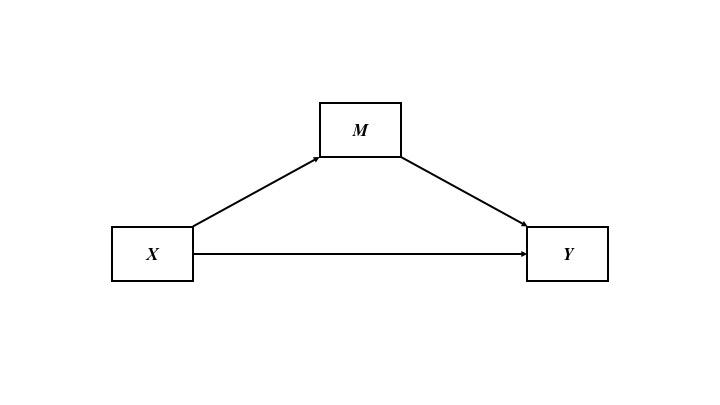
Figure 1. Room temperature is associated with water drinking indirectly through thirstiness
Write model to test indirect effect using sem() from lavaan
~= Regress onto …- Within the regression models, I label coefficients with the astrix.
:== Define a new parameter. Note when you define new parameter with:=, you can use the astrix to multiply values- For more details about lavaan syntax, see the tutorials tab at the lavaan website (linked in Resources below)
mod1 <- "# a path
thirst ~ 1 + a * room_temp
# b path
consume ~ 1 + b * thirst
# c prime path
consume ~ cp * room_temp
# indirect and total effects
ab := a * b
total := cp + ab"Set random seed so results can be reproduced
set.seed(1234)Fit model
You must specify bootstrapping in the
sem()function
sem.fit1 <- sem(mod1, data = thirst.dat, se = "bootstrap", bootstrap = 10000)Summarize model
standardized = TRUEadds standardized estimate to the model output. Also, seehelp("standardizedsolution")
summary(sem.fit1, standardized = TRUE)## lavaan 0.6-3 ended normally after 45 iterations
##
## Optimization method NLMINB
## Number of free parameters 7
##
## Number of observations 50
##
## Estimator ML
## Model Fit Test Statistic 0.000
## Degrees of freedom 0
##
## Parameter Estimates:
##
## Standard Errors Bootstrap
## Number of requested bootstrap draws 10000
## Number of successful bootstrap draws 10000
##
## Regressions:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## thirst ~
## room_temp (a) 0.761 0.148 5.146 0.000 0.761 0.557
## consume ~
## thirst (b) 0.348 0.135 2.566 0.010 0.348 0.377
## room_temp (cp) 0.036 0.189 0.190 0.850 0.036 0.029
##
## Intercepts:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .thirst -50.137 10.392 -4.825 0.000 -50.137 -41.212
## .consume -0.610 13.068 -0.047 0.963 -0.610 -0.543
##
## Variances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .thirst 1.020 0.157 6.493 0.000 1.020 0.689
## .consume 1.065 0.208 5.130 0.000 1.065 0.845
##
## Defined Parameters:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## ab 0.264 0.123 2.142 0.032 0.264 0.210
## total 0.300 0.176 1.708 0.088 0.300 0.238Print all model parameters
In the boot.ci.type argument, I ask for bia-corrected and accelerated confidence intervals.
parameterestimates(sem.fit1, boot.ci.type = "bca.simple", standardized = TRUE) %>%
kable()| lhs | op | rhs | label | est | se | z | pvalue | ci.lower | ci.upper | std.lv | std.all | std.nox |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| thirst | ~1 | -50.1370968 | 10.3917984 | -4.8246795 | 0.0000014 | -70.5071001 | -29.1342980 | -50.1370968 | -41.2124397 | -41.2124397 | ||
| thirst | ~ | room_temp | a | 0.7610887 | 0.1478894 | 5.1463382 | 0.0000003 | 0.4615386 | 1.0516483 | 0.7610887 | 0.5573208 | 0.6256111 |
| consume | ~1 | -0.6095498 | 13.0681341 | -0.0466440 | 0.9627970 | -28.2155834 | 23.5558529 | -0.6095498 | -0.5431164 | -0.5431164 | ||
| consume | ~ | thirst | b | 0.3475013 | 0.1354310 | 2.5658927 | 0.0102911 | 0.0649464 | 0.5977807 | 0.3475013 | 0.3766787 | 0.3766787 |
| consume | ~ | room_temp | cp | 0.0359239 | 0.1894877 | 0.1895842 | 0.8496349 | -0.3163420 | 0.4346034 | 0.0359239 | 0.0285146 | 0.0320086 |
| thirst | ~~ | thirst | 1.0203024 | 0.1571380 | 6.4930348 | 0.0000000 | 0.7538658 | 1.3725825 | 1.0203024 | 0.6893935 | 0.6893935 | |
| consume | ~~ | consume | 1.0647750 | 0.2075633 | 5.1298811 | 0.0000003 | 0.7421153 | 1.6034916 | 1.0647750 | 0.8453279 | 0.8453279 | |
| room_temp | ~~ | room_temp | 0.7936000 | 0.0000000 | NA | NA | 0.7936000 | 0.7936000 | 0.7936000 | 1.0000000 | 0.7936000 | |
| room_temp | ~1 | 70.0800000 | 0.0000000 | NA | NA | 70.0800000 | 70.0800000 | 70.0800000 | 78.6671223 | 70.0800000 | ||
| ab | := | a*b | ab | 0.2644793 | 0.1234479 | 2.1424364 | 0.0321584 | 0.0644499 | 0.5583697 | 0.2644793 | 0.2099308 | 0.2356543 |
| total | := | cp+ab | total | 0.3004032 | 0.1758694 | 1.7081041 | 0.0876170 | 0.0007142 | 0.7019998 | 0.3004032 | 0.2384455 | 0.2676630 |
Interpretation
Every 1°F increase in room temperature was associated with an a = 0.76 (S.E. = 0.15) increase in thirstiness units. Adjusting for room temperature, every 1-unit increase in thirstiness was associated with drinking 0.35 (S.E. = 0.14) more deciliters of water. Increases in room temperature were associated with increases in water drinking indirectly through increases in thirstiness. Specifically, for every a = 0.76 unit increase in the association between room temperature and thirstiness, there was an ab = 0.26 (S.E. = 0.12) increase in deciliters of water people drank. Importatnly, a bias-corrected bootstrapped confidence interval with 10,000 samples was above zero, 95% CI []. Last, there was no sufficient evidence that room temperature was associated with how many deciliters of water people drank independent of its association with thirstiness, c’ = 0.04 (S.E. = 0.19).
Test same model using mediation() from MBESS
The syntax for
mediation()doesn’t have as steep a learning curve as lavaan, but lavaan (and SEM in general) has a gazillion-fold more flexability in specifying more involved models.
with(thirst.dat, mediation(x = room_temp, mediator = thirst, dv = consume, bootstrap = TRUE, which.boot = "BCa", B = 10000))## [1] "Bootstrap resampling has begun. This process may take a considerable amount of time if the number of replications is large, which is optimal for the bootstrap procedure."## Estimate CI.Lower_BCa
## Indirect.Effect 0.26447934 0.067266940
## Indirect.Effect.Partially.Standardized 0.23328589 0.049494759
## Index.of.Mediation 0.20993085 0.051674603
## R2_4.5 0.05629571 -0.026310687
## R2_4.6 0.03221379 0.001860142
## R2_4.7 0.20827151 0.043495582
## Ratio.of.Indirect.to.Total.Effect 0.88041445 0.095311306
## Ratio.of.Indirect.to.Direct.Effect 7.36221455 3.153580178
## Success.of.Surrogate.Endpoint 0.39470199 -0.033430066
## Residual.Based_Gamma 0.11312492 0.019489023
## Residual.Based.Standardized_gamma 0.10885100 0.018547109
## SOS 0.99014119 0.917763141
## CI.Upper_BCa
## Indirect.Effect 0.5650835
## Indirect.Effect.Partially.Standardized 0.4675337
## Index.of.Mediation 0.4328584
## R2_4.5 0.2023460
## R2_4.6 0.1141848
## R2_4.7 0.4346039
## Ratio.of.Indirect.to.Total.Effect 7.2734388
## Ratio.of.Indirect.to.Direct.Effect 7784.3084246
## Success.of.Surrogate.Endpoint 0.9278002
## Residual.Based_Gamma 0.2163837
## Residual.Based.Standardized_gamma 0.2098652
## SOS 1.0000000Plot the mediation effect
with(thirst.dat, mediation.effect.plot(x = room_temp, mediator = thirst, dv = consume, ylab = "Water Drank (dl)", xlab = "Thirstiness (1/5 = Not at all thirty/Very thirsty)"))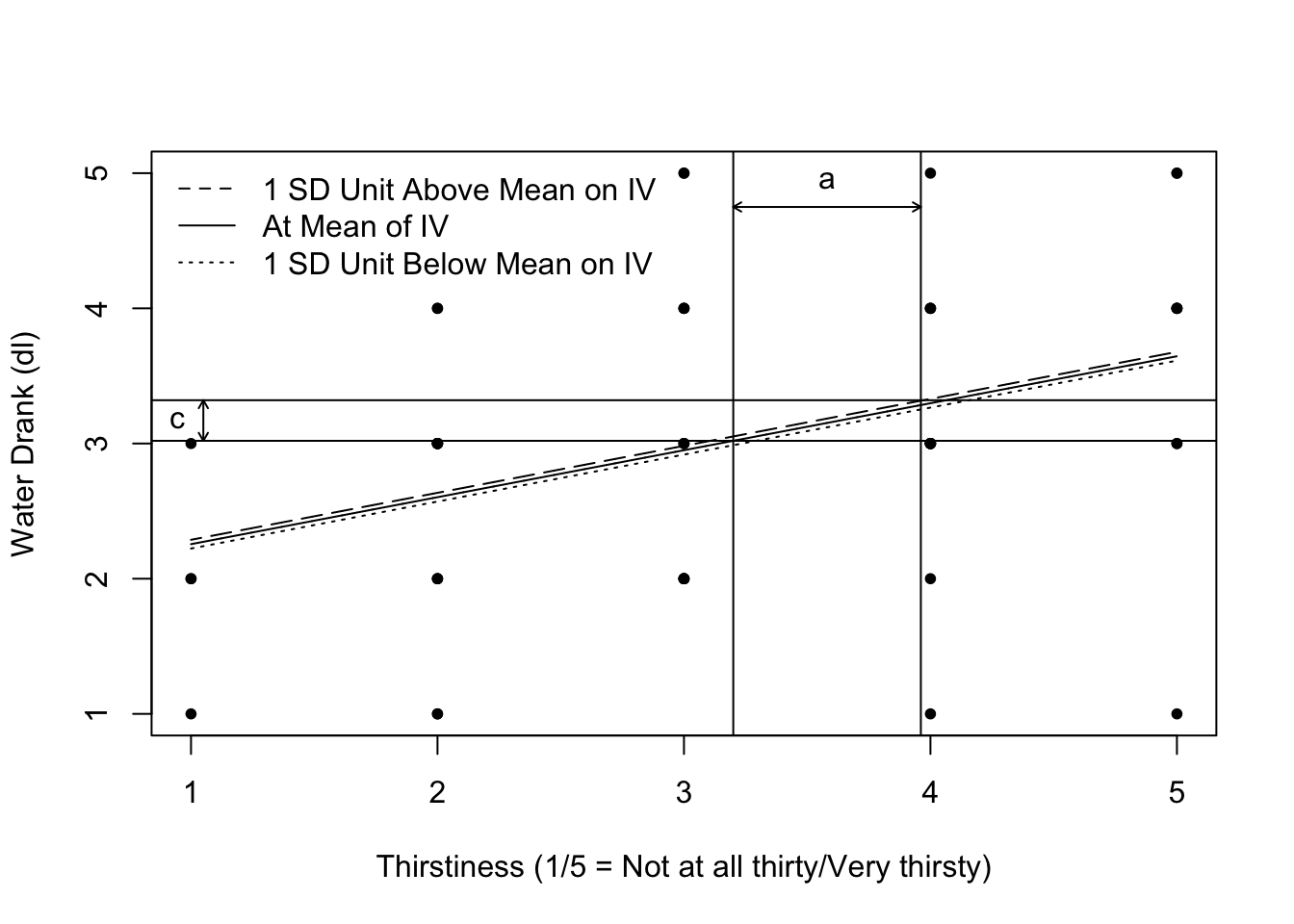
The plot above depicts the relationship between the proposed mediator (thirstiness) and outcome variable (water drank, in dl) at different levels of the proposed antecedent (room temperature, in °F). The plot doesn’t label this, but if check out the right triangle formed in between the vertical lines marking the a coefficient, you’ll see the indirect effect, which is the height of this triangle.
Test the same model using mediate() from psych
mediate(consume ~ room_temp + thirst, data = thirst.dat, n.iter = 10000) %>%
print(short = FALSE)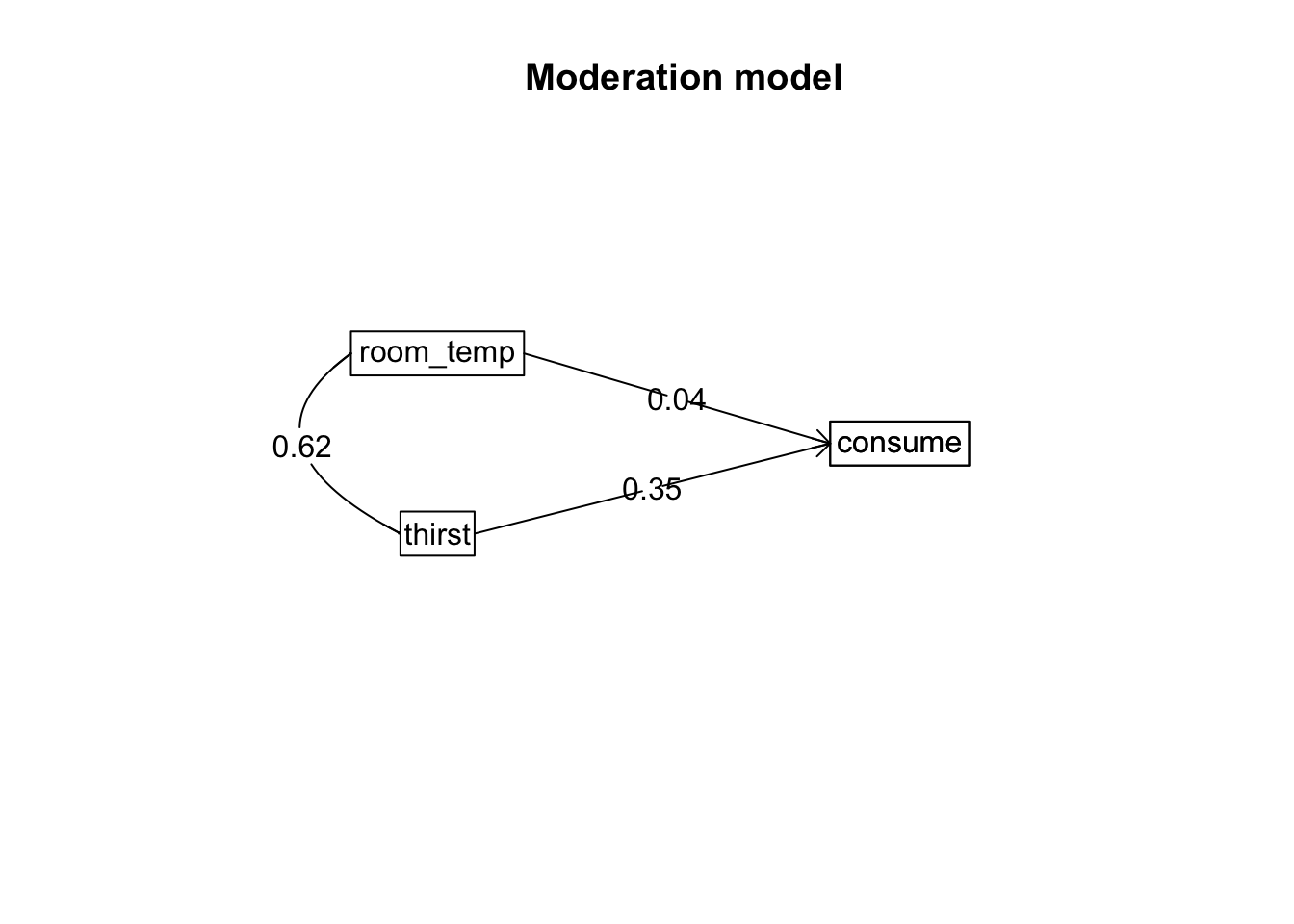
##
## Mediation/Moderation Analysis
## Call: mediate(y = consume ~ room_temp + thirst, data = thirst.dat,
## n.iter = 10000)
##
## The DV (Y) was consume . The IV (X) was room_temp thirst . The mediating variable(s) = .
## DV = consume
## slope se t p
## room_temp 0.04 0.20 0.18 0.860
## thirst 0.35 0.15 2.33 0.024
##
## With R2 = 0.15
## R = 0.39 R2 = 0.15 F = 4.3 on 2 and 47 DF p-value: 0.0193Resources
- MacKinnon, D. P. (2008). Introduction to statistical mediation analysis. New York, NY: Lawrence Erlbaum Associates.
- Revelle, W. (2017) How to use the psych package for mediation/moderation/regression analysis. [.pdf]
- Rosseel, Y. (2012). Lavaan: An R package for structural equation modeling and more. Version 0.5–12 (BETA). Journal of statistical software, 48(2), 1-36. [website]
- Rucker, D. D., Preacher, K. J., Tormala, Z. L., & Petty, R. E. (2011). Mediation analysis in social psychology: Current practices and new recommendations. Social and Personality Psychology Compass, 5(6), 359-371. [.pdf]
General word of caution
Above, I listed resources prepared by experts on these and related topics. Although I generally do my best to write accurate posts, don’t assume my posts are 100% accurate or that they apply to your data or research questions. Trust statistics and methodology experts, not blog posts.
Nicholas M. Michalak
Data Scientist | Ph.D. Social Psychology
I study how both modern and evolutionarily-relevant threats affect how people perceive themselves and others.